Infix Notation
Aleph bevorzugt die
postfix-Notation. Die Gründe sind in der Dokumentation
ausreichend dargelegt. Aber Aleph hat nicht den Anspruch den Anwender
zu "belehren".
Die gewohnte Schreibweise ist nun einmal die infix-Notation. Weil
Gewohnheiten ein nicht zu unterschätzendes Hilfsmittel sind, ist
auch diese Schreibweise möglich.
Gegebenheiten
Die infix-Notation ist an
viele Voraussetzungen gekoppelt. Viele davon werden überhaupt
nicht mehr als solche wahrgenommen. Um den Anwender möglichst
wenig einzuengen, hier die wichtigsten Voraussetzungen zur
Interpretation von infix-Ausdrücken.
Es gibt unäre und
binäre Operatoren.
So ist + stets binär,
denn 3+4. Aber – kann unär sein, denn 3 + -4.
Unäre Operatoren
sind stets prefix.
So muss 4! (Fakultät)
als Funktion realisiert werden.
Operatoren haben
Prioritäten.
Weil 3+4*5 = 23 und 3*4+5 =
35 ergibt.
Namen von Operatoren
haben (fast immer) die Länge 1.
Die Ausnahmen sind "!=",
"<>"
für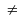 ,
"<=" für
,
"<=" für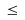 und
">=" für
und
">=" für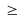
Eine weitere Gegebenheit ist
noch vorhanden. Wird in dem Term eine Funktion mit einem Vorzeichen
versehen, so ist stets der gelieferte Funktionswert gemeint und nicht
die Funktion selbst.
Ein Beispiel:
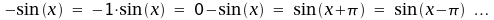
Weil sich derartige Probleme
bei vielen Funktionen finden und Mehrdeutigkeiten immer zu Problemen
führen, gilt bei Aleph
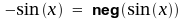
bei "neg"
handelt es sich um eine Funktion mit einem Argument. Der Name steht
für negativ und nicht für Negation. Weil Zahlen in
Aleph über eine Identitätsfunktion definiert sind,
entspricht der
kalkulatorische Term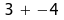 dem
funktionalen Term
dem
funktionalen Term .
.
Dem Anwender sollen diese
Details beim Entwurf eines Programms nicht zugemutet werden. Deshalb
übernimmt das Java-Programm "HandleTerm"
die notwendigen Arbeiten. Wird aber auf der entsprechende Term in
seiner post- oder prefix-Notation ausdrücklich verlangt, ist die
"neg"-Funktion vorhanden.
Einrichten der infix-Notation
Weil Aleph keine syntaktischen
macht, sind Operatoren und Funktionen allein Sache des Anwenders. Bei
der infix-Notation ist diese Freiheit allerdings nicht mehr gegeben,
denn es gibt Regeln (siehe Gegebenheiten). Trotzdem soll weiterhin
ein möglichst hohes Maß an Freiheit vorhanden sein. Die
Bezeichnungen der Operatoren und Funktionen bleiben dem Anwender
überlassen. Diese Freiheit ist bei Funktionen weitgehend auch in
anderen Sprachen vorhanden, bei Operatoren aber selten.
Dieser Abschnitt zeigt die
Einrichtung einer einfachen Grundlage für die Umsetzung von
infix- in postfix-Notation. Dabei werden auch Bezeichner verwendet,
die im einfachen Aleph überhaupt nicht vorhanden sind. Sie sind
aber für die Entwicklung eigener Lösungen sehr hilfreich.
Natürlich werden diese "Unbekannten" auf ihre
Notwendigkeit hin untersucht und besprochen.
Übersetzer bereitstellen
Der Übersetzer ist sehr
einfach gehalten und in Java programmiert. Es ist also ein in
Maschinensprache geschrieben. In den Kernel wurde es nicht
aufgenommen weil nur die wesentlichen Punkte einer Übersetzung
gezeigt werden. Die Verwendung der infix-Notation ist prinzipiell ein
Wechsel der Sprache.
Anwender mit derartigen
Motiven sollten den hier vorhandenen Übersetzer als Minimum
betrachten ansehen und mit entsprechenden Generatoren eigene Lösungen
erzeugen (z.B. javaCC).
In der Datei "infix.vvm"
ist die Bereitstellung des Übersetzers namens "HandleTerm"
vorhanden.
"parsing.HandleTerm" classify instantiate
|
Zunächt wird eine Instanz
erzeugt. In diesem Objekt sind die Methoden zur Übersetzung von
in- nach postfix vorhanden.
Funktionen bereitstellen
Die Funktionen, zumindest
deren Namen, sind in einer eigenen Klasse gekapselt. Der Anwender
muss allerdings die Namen seiner Funktionen mitteilen.
"parsing.Functions" classify instantiate
dup "append { String }" method app
"neg" app
"not" app
"abs" app
"cos" app
"cot" app
"exp" app
"ln" app
"sin" app
"sqrt" app
"tan" app
"xyz" app
"app" find drop forget // Methode vergessen
|
Für die Erweiterung der
Liste mit Funktionen steht in der Klasse "Functions"
die Methode "append"
bereit. Damit diese Methode einfach in Aleph verwendet werden kann,
wird sie als Aleph-Methode "app"
ins Wörterbuch aufgenommen.
Die Funktion "neg"
wurde bereits erwähnt. Es ist dem Anwender überlassen, die
entsprechende Formulierung zu finden. Der Übersetzer geht
allerdings von diesem Namen aus. Die Funktion "xyz"
ist hohl (nix, dummy) und spielt bei den Operatoren als Beispiel eine
wichtige Rolle.
Nachdem die Namen der
Funktionen feststehen, sollte die Aleph-Methode "app"
vergessen werden.
Die Funktionen müssen
jetzt noch dem Übersetzer zur Verfügung gestellt werden. Es
genügt die "Functions"
an entsprechender Stelle im Übersetzer zu speichern.
1 ndup // Übersetzer nach oben duplizieren
"functions" // Name des Fields
swap // Übersetzer nach oben kopieren
store // Übersetzer field functions Übersetzer --> Übersetzer
|
Operatoren bereitstellen
Die Bereitstellung der
Operatoren ist prinzipiell dem eben beschriebenen Vorgang ähnlich.
"parsing.Operators" classify instantiate
dup "append { String int }" method app
"(" 100 app
")" 100 app
"," 150 app
"<" 200 app
">" 200 app
"=" 200 app
"!=" 200 app
"<>" 200 app
"<=" 200 app
">=" 200 app
"|" 300 app
"+" 300 app
"-" 300 app
"&" 400 app
"*" 400 app
"/" 400 app
"!" 500 app
"^" 500 app
"app" find drop forget // Methode vergessen
1 ndup "operators" swap store
|
Die Namen der Operatoren sind
um ihre Priorität erweitert. Dieser Wert ist für eine
korrekte Übersetzung sehr wichtig. In dieser Beschreibung wird
noch auf die Mechanismen der Übersetzung eingegangen, damit der
Anwender seine Operatoren auch mit der entsprechenden Gewichtung
ausstatten kann.
Vier Operatoren haben
Bezeichner aus zwei Zeichen. Sie wurden bereits im Abschnitt
Gegebenheiten besprochen. Die Erkennung dieser Namen ist fest im
Übersetzer verankert.
Funktionsargumente
Funktionen haben ein oder
mehrere Argumente. Der ','-Operator
(Komma) gestattet die Unterscheidung der Argumente. Aleph lässt
auch die Formulierung von Funktionen zu, deren Argumentanzahl
unbekannt ist. Trotzdem muss die korrekte Zuordnung gewährleistet
sein. Das Java-Programm "testÜbersetzer"
zeigt ein Beispiel mit der Funktion "xyz".
Die Realisation des
','-Operators ist dem Anwender
überlassen. Dabei muss das Einsatzgebiet berücksichtigt
werden. So kann die Übersetzung gleich mit einer Kompilierung
versehen werden. Dann muss die Bearbeitung der Argumentlisten mit
einem rekursiven Argumentzähler ausgestattet werden ("Rekursion
in Aleph"). Dann könnten Java-Methoden wie im
Java-Quelltext aufgerufen werden. Es ist aber auch möglich von
der Bekanntheit der Argumentanzahl auszugehen und den ','-Operator
ohne Funktionalität einzusetzen.
Die korrekte Zuordnung der
Argumente wird bei der Wandlung eines postfix- in einen
prefix-Ausdruck deutlich. Am Ende der Datei "infix.vvm"
ist ein Beispiel vorhanden, welches außerdem abschreckend
wirken soll. Die Notation hat wohl doch keine unmittelbaren Einfluss
auf die Lesbarkeit.
Von infix nach postfix
Werden IT-Fachleute danach
gefragt, wie ein Term denn übersetzt wird, kommt stets eine
Antwort mit folgendem sinngemäßen Inhalt:
Es wird eine Baumstruktur
aufgebaut, deren Verzweigungen den Operatoren entsprechen und deren
Zweige stets in einer Zahl enden. Je nach Durchlaufen dieses Baums
ergibt sich die Notation.
Tatsächlich arbeiten
moderne Übersetzer-Generatoren mit dieser Baumstruktur. So
einfach wie eben beschrieben verhält es sich aber nicht. Was ist
mit "Punkt- vor Strichrechnung"?
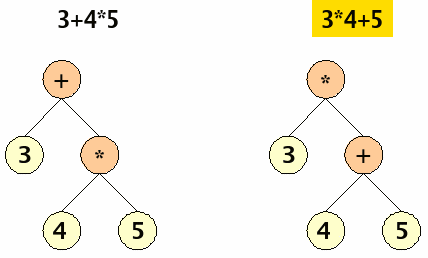
Die Bäume werden nun von
oben nach unten durchlaufen. Verzweigungen werden zuerst nach links
(vom Betrachter aus gesehen) betreten. Operatoren erzeugen immer
einen geklammerten Term mit zwei Elementen und dem Operator links vor
der Klammer.
-
|
linker Baum |
rechter Baum |
|
+()
+(3, )
+(3, *())
+(3, *(4, 5)) |
*()
*(3, )
*(3, +())
*(3, +(4, 5)) |
Der rechte Baum ist falsch.
Allein die Anwendung einer Baumstruktur genügt offenbar nicht.
Übersetzung mit Stack
Der verwendete Übersetzer
arbeitet ohne Baumstruktur. Die Vorgehensweise ist strikt an die
erlernten (und daher gewohnten) Einzelschritte orientiert. Weil sich
hier etwas gemerkt werden muss, arbeitet das Programm mit einem
Stack. Was zuletzt in diesem Kurzzeitgedächtnis abgelegt wurde,
ist zuerst wieder im Zugriff.
Die Bearbeitung der Terms
(Quelle) erfolgt von links nach rechts. Die Bearbeitung des Stacks
von oben nach unten. Das Programm ist höchstens mit zwei
Elementen konfrontiert, die mit "Quellenelement" und
"Stackelement" bezeichnet sind. Das Ergebnis wird mit
"Ziel" bezeichnet, an das einzelne Elemente angehängt
werden.
Hier die einfachen Regeln,
nach denen der Übersetzer vorgeht:
Wenn
Quellenelement kein Operator ist,
dann Quellenelement
ins Ziel überführen, nächstes Quellenelement holen.
Wenn Stack leer
ist,
dann Quellenelement
auf Stack, nächstes Quellenelement holen.
Wenn
Quellenelement "(" ist,
dann Quellenelement
auf Stack, nächstes Quellenelement holen.
Wenn
Quellenelement ")" ist und Stackelement "("
ist,
dann Stackelement
entfernen, nächstes Quellenelement holen.
Wenn Priorität(
Quellenelement) > Priorität( Stackelement),
dann Quellenelement
auf Stack, nächstes Quellenelement holen.
Wenn Priorität(
Quellenelement) <= Priorität( Stackelement),
dann Stack ins Ziel
überführen.
Wenn Quelle LEER
ist,
dann alle
Stackelemente ins Ziel überführen.
Diese Regeln gestatten bereits
die Übersetzung einfacher Terme. Leider werden keine Funktionen
berücksichtigt. Ihre Namen wären von Variablen oder
Konstanten nicht zu unterscheiden. Sollen auch noch Argumente
berücksichtigt werden, die ja wieder Funktionen sein können,
ist das Regelwerk total überfordert.
Es zeigt sich jedoch, dass die
infix-Notation sehr viel leistungsfähiger ist als zunächst
angenommen. Bereits kleine Änderungen an den aufgestellten
Regeln genügen für einen reibungslosen Ablauf. So werden
jetzt auch einzelne Zeichen der Elemente berücksichtigt. Um die
Sache abzurunden werden noch Wiederholungen(Schleifen) eingebaut.
Verfeinerte Regeln für
die Wandlung von Infix nach postfix:
Solange die Quelle
nicht leer ist
Wenn das letzte
Zeichen des Quellenelements kein Operator ist,
dann Quellenelement
ins Ziel überführen, nächstes Quellenelement holen.
sonst
Wenn Stack leer
ist,
dann Quellenelement
auf Stack ablegen, nächstes Quellenelement holen.
sonst
Wenn das letzte
Zeichen des Quellenelements '(' ist,
dann Quellenelement
auf Stack ablegen, nächstes Quellenelement holen.
sonst
Wenn das letzte
Zeichen des Quellenelements ')' ist
und das letzte
Zeichen des Stackelements '(' ist,
dann Stackelement
entfernen, nächstes Quellenelement holen.
sonst
Wenn Priorität
des letzten Zeichens des Quellenelements > der Priorität
des letzten Zeichens des Stackelements,
dann Quellenelement
auf Stack ablegen, nächstes Quellenelement holen.
sonst
Stackelement ins Ziel
überführen.
Quelle ist leer
Solange der Stack
nicht leer ist
Stackelement nach Ziel
überführen.
Stack ist leer
Diese 7 Regeln sind auch im
Quelltext des Java-Programms als Kommentar vorhanden. Es dürfte
sehr einfach sein sie zu erweitern oder eigenen Wünschen
anzupassen.